
Machine learning has been hyped (and in some cases overhyped). However, one successful DevOps use case for machine learning is application performance management. Why? Simply put, machine learning is needed to analyse the volume, velocity, and variety of big data generated by today’s dynamic application environments. By applying machine learning to identify patterns and anomalies, DevOps teams can better troubleshoot intermittent and complex problems, understand usage patterns, reduce bug rates, and improve the customer experience.
What’s changed?
Modern applications based on containers, microservices, cloud services, and ever-smaller slices of computing and storage functions create a complex mesh of dependencies that are constantly changing. Performance issues can surface at the user or server end, with the root causes hiding somewhere downstream among thousands of objects, methods, and transactions per second. Is the problem with the company’s code, the network, the infrastructure, or the end user’s device? The best approach is the combination of big data and machine learning, collecting data on the full breadth and depth of individual transactions and unleashing the powers of machine learning to identify and classify critical anomalies and bottlenecks.
Machine learning needs big data
When trying to understand and optimise application performance, more data is better. Whether testing an upcoming release or troubleshooting a reported problem, teams and tools often use data samples and averages to create a baseline of normal behaviour and isolate the outliers. However, data samples at one-minute or five-minute intervals in a sub-second world not only miss many of the outliers, they often misrepresent them. Big data, collecting system and resource data every second from all apps, all devices, all transactions, is essential for training machine learning algorithms. Otherwise, they are learning the simulation, not the real world.
Machines must be taught, again and again
In machine learning, the analytic engine builds its models by analysing massive amounts of data in order to isolate patterns, clusters, and correlations. One approach is to start with common scenarios, teaching the computer to pick out signatures that are indicative of typical application performance problems. Since there are many possible scenarios to be learned, APM tools use a variety of anonymised real-world data sets from a broad group of organisations in different industries for the initial training. Subject-matter experts then review the results and tell the computer what the correct classifications are for each cluster or pattern. Then the computer explores on its own and the experts identify whether a cluster it found is a problem or not.
Teaching is an iterative process, isolating sets of transactions, isolating commonalities, removing transactions with that characteristic, and evaluating the remainder to see if the issue is still present. This enables the tool to catch unanticipated issues which are incorporated into the list of automatic insights. The bigger the data and the more metadata and richness in it, the more accurately the system can pinpoint patterns and causes.
APM big data and machine learning example
For example, the chart below is a plot of detailed response-time data points collected from 10,000 individual transactions. Humans see a mostly ‘normal’ distribution curve, with a sizeable collection of outliers. Trying to sort these into logical sets would take the DevOps or QA team weeks or months, long after the related issues have impacted the business.

Machine learning can quickly group the outliers into sets, excluding transactions that have no exceptions and identifying areas for further investigation, such as web service timeouts, database timeouts, authorisation timeouts, and initialisation failures. Exploring further, machine learning iteratively groups and regroups sets, looking at all interdependencies, isolating commonalities, and providing details of methods, database calls, servers, or other characteristics that are consistently associated with underperforming transactions. Performing these tasks much faster than humans, the computer learns the most likely characteristics to isolate based on statistical results instead of guesses and anecdotes.

Help for DevOps teams
With a big data foundation, machine learning systems can synchronise multiple data sources based on their metadata, linking server statistics, log file entries, and transactions. Armed with this info, DevOps teams can quickly identify and prioritise the users, transactions, and application components with the biggest impact on the business. Historical data enables rapid comparisons of performance before and after releases, providing insight on the impact of development changes and the effectiveness of testing coverage. Machine learning techniques can also turn complex interdependencies into graphical visualizations that humans find much faster and easier to process than reams of tabular data.
For example, when a series of anomalous transactions are identified, detailed data enables the machine to compare key metrics and examine individual users, transactions with similar errors, or transactions running through a specific geography. Linking logs to transaction data synchronise the data, enabling DevOps to quickly drill into the offending method, server, or network.
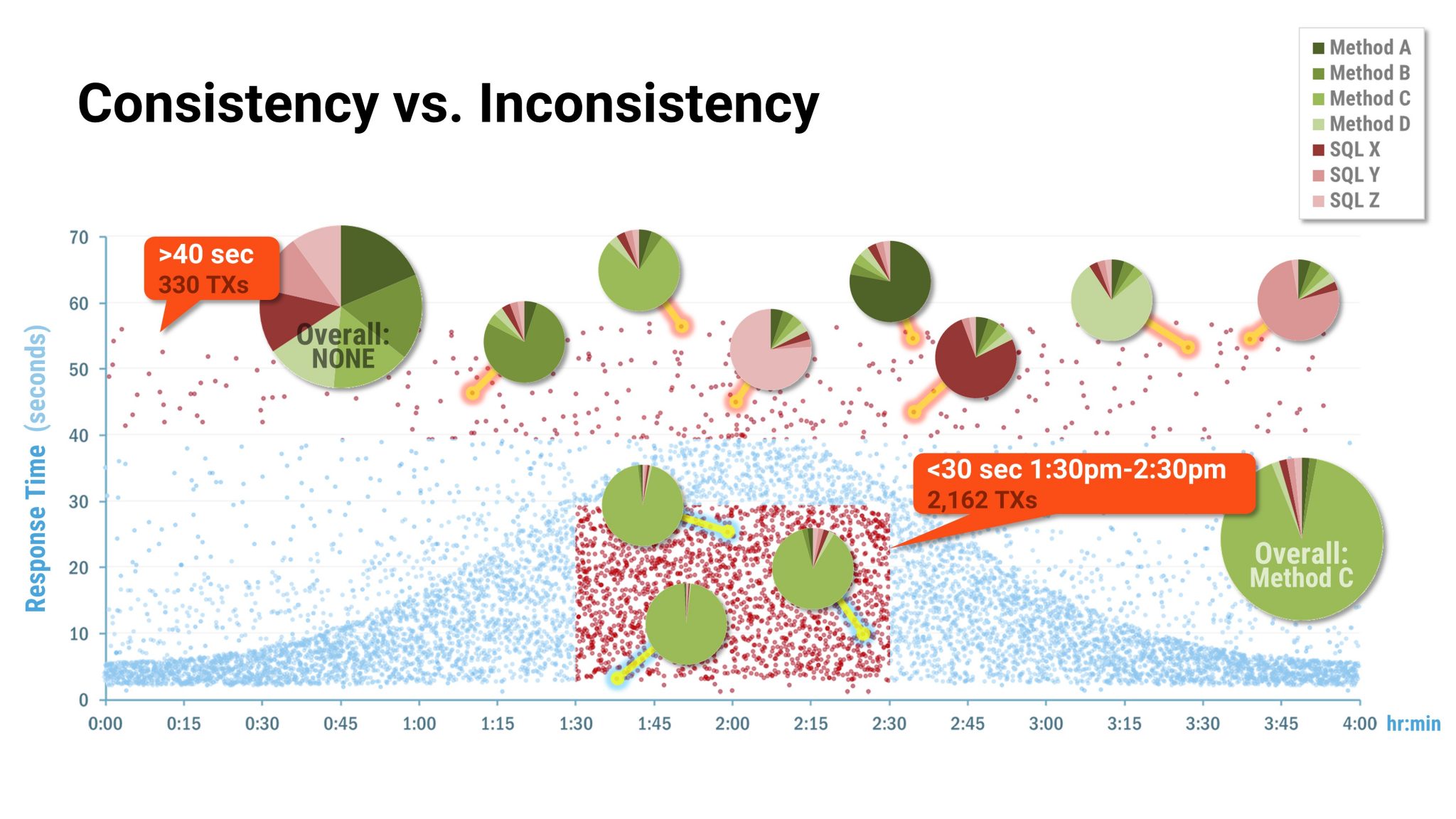
In the chart above, machine learning separates consistent and inconsistent characteristics, isolating Method C as the single biggest cause of slowdowns. An important truism is that all slow transactions may be slow for different reasons, and machine learning automates the early stages of data analysis and discovery, enabling the team to focus their resources on resolving the most impactful issues.
Machine learning: making sense of APM big data
This is just the beginning of the machine-learning era for APM. However, existing machine learning techniques are already delivering significant value to DevOps teams by analysing APM big data and surfacing the probable causes of performance issues. This rapid identification of issues improves performance reliability, reduces bug rates when used in development environments, and increases user satisfaction with their online experiences.
Data quality matters. Because big data is the foundation of machine learning, it is important to collect all relevant metrics as well as the associated metadata before applying machine learning, and not rely on sampling algorithms that may miss issues in dynamic application environments.
Written by Gayle Levin, Director of Solutions Marketing, Riverbed Technologies



